GRASS GIS Standardized Sample Datasets

With the standardized sample datasets one is able to use the same instructions, tutorials and teaching materials for different regions in the world. Using local data makes the topic personal to the audience and may enhance the learning experience. Moreover, the instructions can be written down once with the standardized name and doesn't need to be changed when we start to use some new data. This wouldn't be possible if we use names like dem_10m or elevation_italy as we would need to change the instructions when we have data with higher resolution of for smaller region. However, when using standardized names like elevation there is no need to change the instructions as long as the dataset is standardized as well.
The standardized sample datasets concept defines set of basic data and names for individual maps (layers). These standardized names used throughout the instructions make the instructions independent on the particular dataset which is used. A standardized sample dataset for a given region can be used with different teaching materials which were developed following the standardized sample dataset practice.
There are limits to what can be dataset independent in the instructions. For example, a setting of a computational region, specifying coordinates of a point, or providing sample results cannot be independent on given data. However, these steps can be often easily reproduced by the learner on different data especially under advise of an instructor.
GRASS GIS is quite advantageous in this concept as the workflows, including most of the visualizations, can be recoded as commands. These commands can be executed in a command line but they also map one-to-one to use of graphical user interface (GUI). Moreover, the whole set of commands can be executed automatically to check that the instructions work with the given dataset. Similar principles can be applied for other packages especially when Python or R is used, although the translation to GUI is often not as smooth as in case of GRASS GIS and its command line or Python interface (or rgrass7 for that matter). Finally, even applications or courses which are using only GUI can benefit from using a standardized set of names as the sentence or screenshot containing text and now add the elevation layer will always work regardless the particular dataset used.

List of datasets
Already published:
- North Carolina GRASS Sample Location (2007, map names partially standardized, content partially standardized, currently used dataset, to be deprecated)
- Piemonte, Italy (2012, map names not standardized, content not standardized, see below for a new standardized version)
- Spearfish, USA (to be phased out, 1986)
Planning - Future standardized datasets
- GRASS GIS North Carolina USA Sample Dataset (reference for other datasets, under development)
- GRASS GIS Piemonte Italy Sample Dataset
- GRASS GIS World Sample Dataset
Examples
Computing slope and aspect

Compute slope, aspect and profile curvature of the terrain:
g.region raster=elevation r.slope.aspect elevation=elevation slope=slope aspect=aspect pcurvature=profile_curvature
Visualizing shaded relief
Visualize digital elevation model with shaded relief:
g.region raster=elevation r.relief input=elevation output=shade d.shade shade=shade color=elevation
-

North Carolina, USA
-
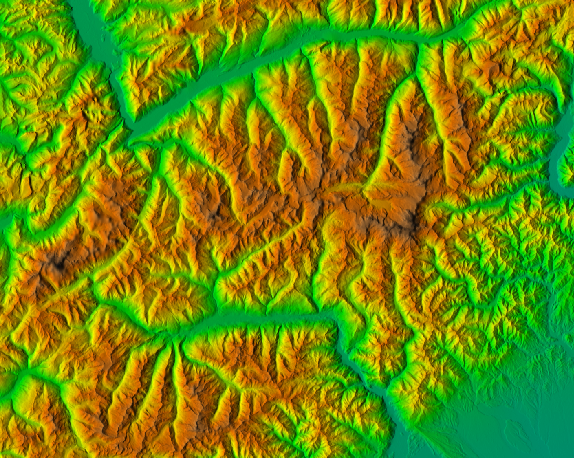
Piemonte, Italy


Where are the datasets used
- GRASS GIS manual (currently using original, not fully compliant North Carolina GRASS Sample Location)
- NCSU Geospatial Modeling and Analysis course and other NCSU OSGeoREL courses (currently using original, not fully compliant North Carolina GRASS Sample Location)
Internationalization

The basic idea of the standardized datasets is that one would be able to use the same instructions, likely series of commands in case of GRASS GIS, for different locations in the world to make it more interesting and personal to the audience. However, sometimes English names in the dataset might not be appropriate for the audience. In this case, different language versions of the dataset can be kept and maintained with the help of bulk renaming modules (see below). Providing both versions, national one and the English one, gives more options for example, the audience can use one with the provided teaching materials and the other with the generally available materials elsewhere benefiting from the familiar data.
Usages for something else than GRASS GIS
Even courses which teach GRASS GIS and some other software (for example the NCSU courses mentioned elsewhere) and courses using something else than GRASS GIS can use the concept of standardized sample dataset as the main idea is to keep given names and provide basic set of data. A script can be used to provide the dataset in different formats, e.g. GRASS Location for GRASS GIS and GeoTIFFs and SpatialLite for QGIS. GRASS GIS (GRASS Location and Mapset) is a good choice for the primary dataset as it enforces data consistency (coordinate system and topology) and has unified approach to vector, raster and 3D raster data.
Tools to help with managing a dataset

- g.rename for changing names of individual raster and vector maps
- g.rename.many for renaming large amount of maps (to standard names or to/from different language)
- r.in.proj and v.in.proj for importing data with different coordinate system
- Python script std_dataset_display.py for generating some maps and images
Improving the idea and the datasets
GRASS Trac wiki contains a page dedicated to the development of the concept of the datasets and also pages dedicated to development of the particular datasets. The main Trac wiki page for datasets is [1]. If you see some issues with the data or the concept you can open a bug report or a feature request as an issue in GRASS GIS Trac instance with Component set to Datasets. Note that you need an OSGeo userID for both Trac wiki and Trac issues.
References
- Mitasova, H., Petrasova, A., Petras V., Harmon, B., Meentemeyer R. K. Integrating FOSS into GIScience Curriculum & Research. November 11, 2015, UCGIS webinar. (Contains examples of how the standardized sample dataset for North Carolina is used at NCSU.)
- Petras V., Petrasova, A., Cepero-Perez, K., Neteler, M., Delucchi, L., Landa, M., Mitasova, H. Using Free and Open Source Solutions in Geospatial Science Education. FOSS4G Europe 2015. July 16, 2015, Como, Italy. (Contains examples of the different datasets, their usage and authors.)
- Petras, V., Petrasova, A., Harmon, B., Meentemeyer, R.K., Mitasova, H. Integrating Free and Open Source Solutions into Geospatial Science Education. ISPRS International Journal of Geo-Information. 2015, 4, 942-956. doi:10.3390/ijgi4020942 (Contains explanation of usage of the GRASS GIS commands concept to get teaching materials which are easy to maintain.)
Contact
If you are interested in producing and sharing a dataset for your region and you want more information, please contact Vaclav Petras or ideally grass-user mailing list (you must be subscribed to it to post messages).